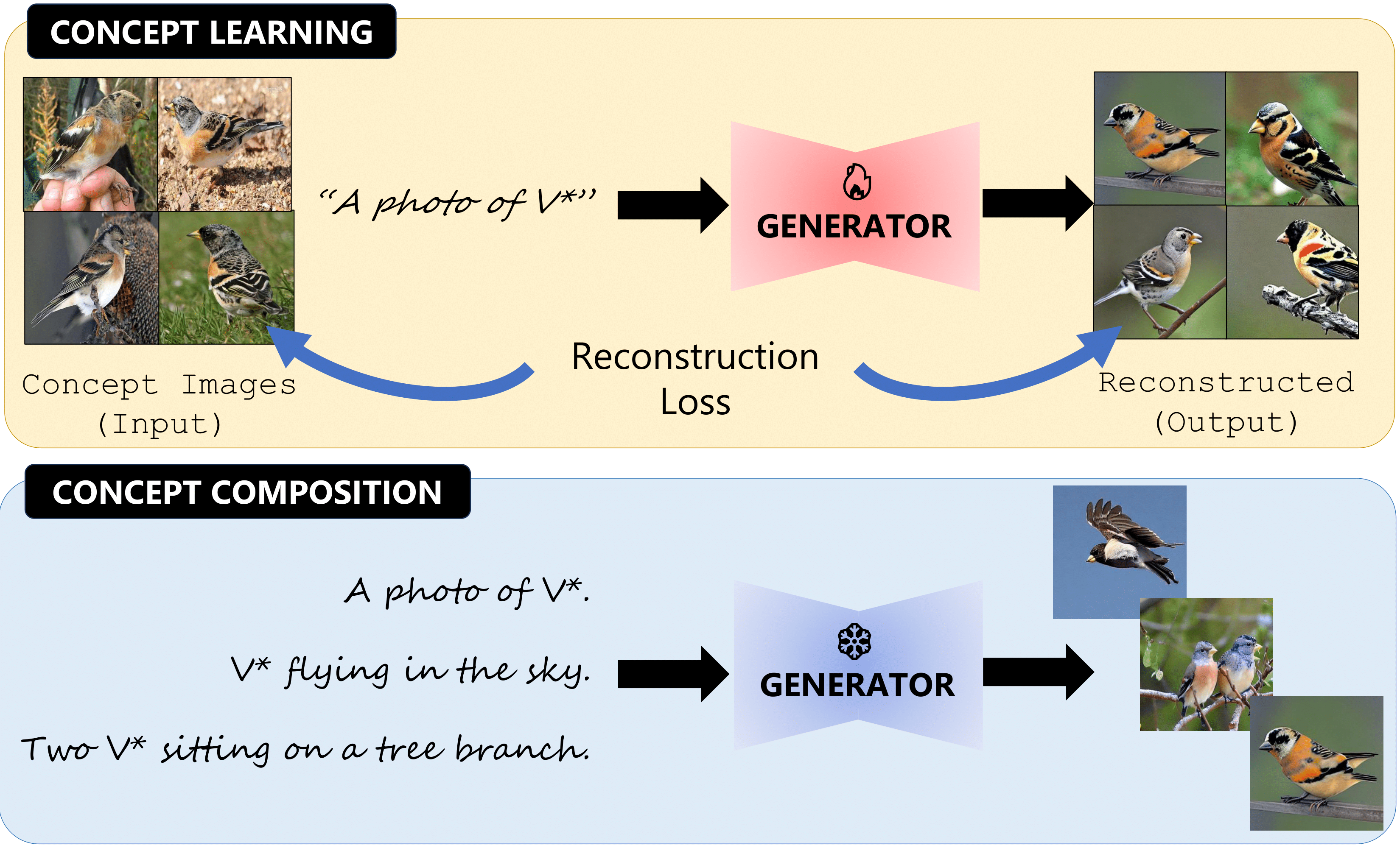
Evaluating Concept Learning Abilities of Text-to-Image Diffusion Models
The ability to understand visual concepts and replicate and compose these concepts from images is a central goal for computer vision. Recent advances in text-to-image (T2I) models have lead to high definition and realistic image quality generation by learning from large databases of images and their descriptions. However, the evaluation of T2I models has focused on photorealism and limited qualitative measures of visual understanding. To quantify the ability of T2I models in learning and synthesizing novel visual concepts, we introduce ConceptBed, a large-scale dataset that consists of 284 unique visual concepts, 5K unique concept compositions, and 33K composite text prompts. Along with the dataset, we propose an evaluation metric, Concept Confidence Deviation (CCD), that uses the confidence of oracle concept classifiers to measure the alignment between concepts generated by T2I generators and concepts contained in ground truth images. We evaluate visual concepts that are either objects, attributes, or styles, and also evaluate four dimensions of compositionality: counting, attributes, relations, and actions. Our human study shows that CCD is highly correlated with human understanding of concepts. Our results point to a trade-off between learning the concepts and preserving the compositionality which existing approaches struggle to overcome.
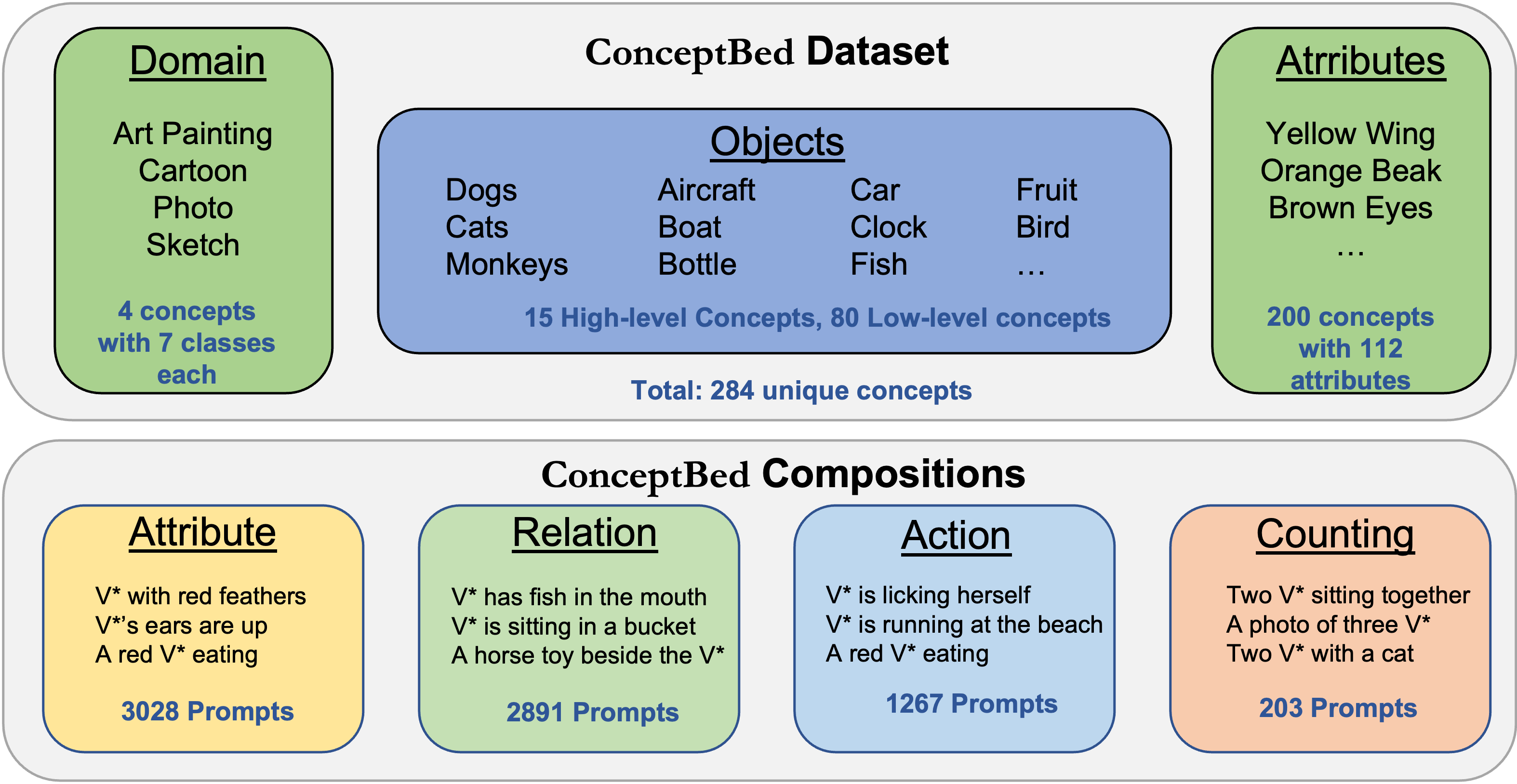

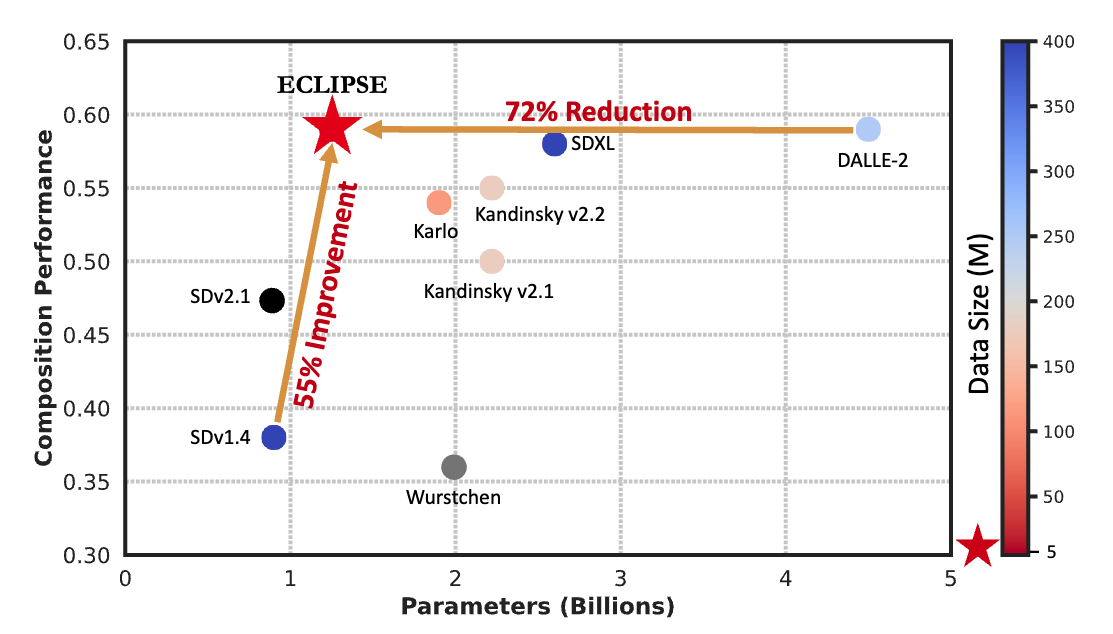
A Resource-Efficient Text-to-Image Prior for Image Generations
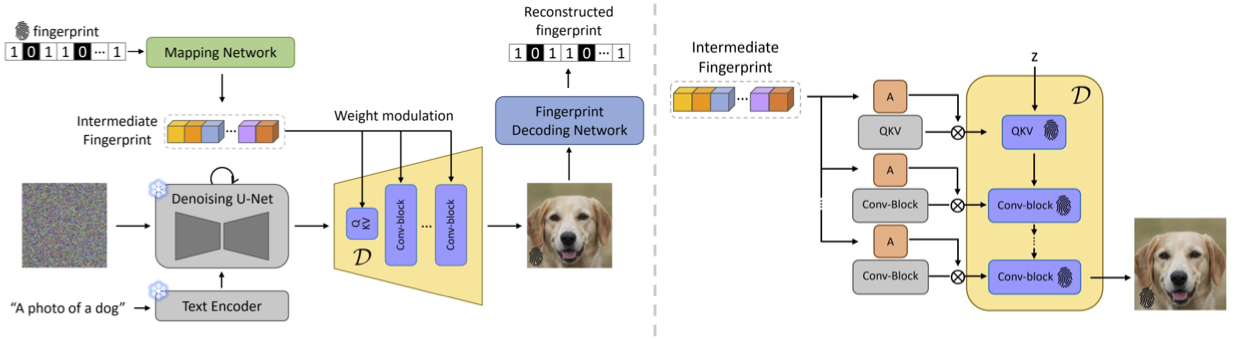
Weight Modulation for User Attribution and Fingerprinting in T2I Models.